
Predicting My Next Favorite Book 📚 Thanks to Goodreads' Data and Machine Learning 👨💻
SimonSays #13 - “If you don’t like to read, you haven’t found the right book.” - J.K. Rowling

Hi! Welcome to SimonSays #13 🚀
This article is quite different than the ones you might be used to. I really enjoyed working on it and sharing it with you, I hope you’ll enjoy reading about it 🙂
If you want to discover more projects I’ve been working on, feel free to check out my website!
As always, if you have any suggestions or feedback feel free to leave a comment below or contact me on Twitter @the_simonpastor
Stay safe!
I recently realized that I didn’t spend enough time reading. So last year I started challenging myself to read more. It’s around that time that I came across Goodreads, a social network for books. Thanks to this platform, you can see what your friends are reading, have read, how they graded various books etc. You can also record all books you’ve read, save books you want to read and so much more.
A few weeks ago, I discovered that I could download my Goodreads data. As a data-enthusiast, I thought it would be fun to have a look at it and see if I could use it to build personalized book recommendations! Here’s how I dit it 👇

Part 1 - Having Fun With The Data
The data I downloaded contained 441 books. It included the ones I had read (265), the ones I’m currently reading (3) and those I want to read (173). For each book it included all (or almost all) of the following details: Book id, Title, Author, ISBN, My Rating, Average Rating (given by all Goodreads members), Publisher, Number of Pages, Year Published.
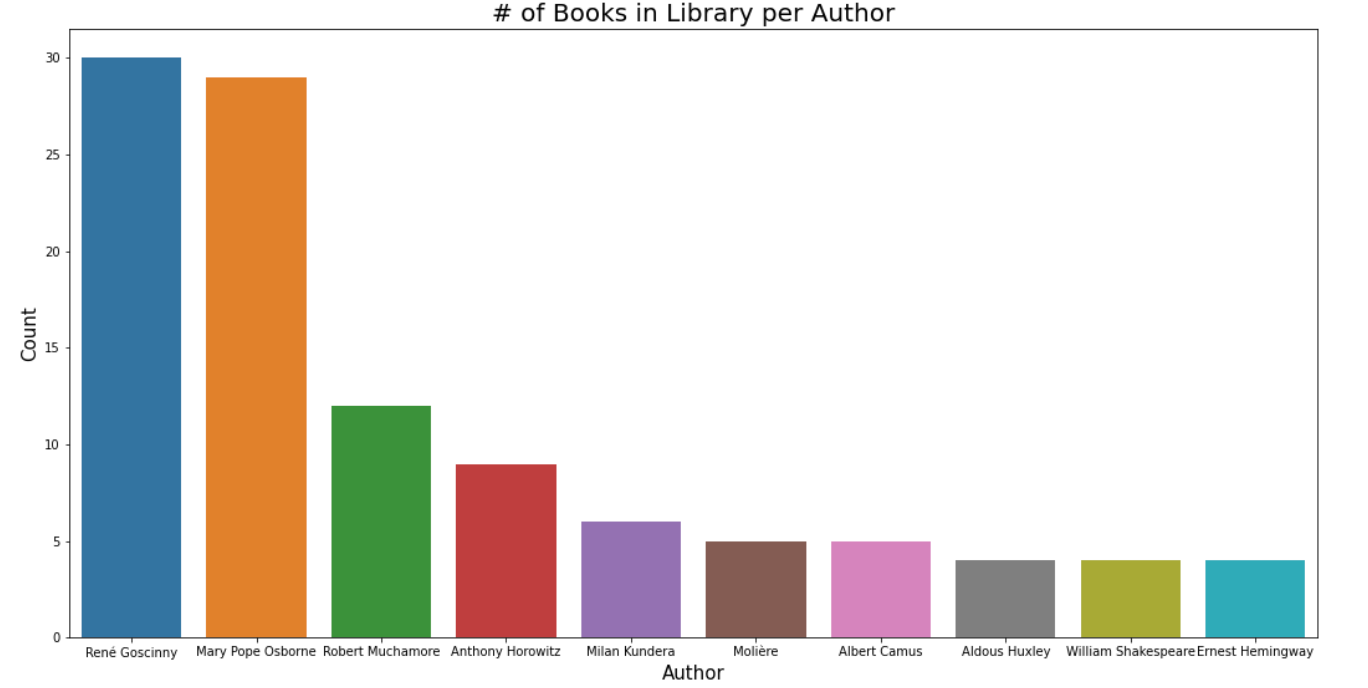
So I started having a bit of fun with the data. Here’s a graph showing the Number of books in my Library per Author. As you can see, childhood book authors René Goscinny (Asterix), Mary Pope Osborne (Magic Tree House), Robert Muchamore (CHERUB) and Anthony Horowitz (Alex Rider) lead the ranking. They are followed by “adult” authors such as Kundera, Camus, Molière and Huxley.
Another interesting graph I was able to display was the number of books in my library per year published.
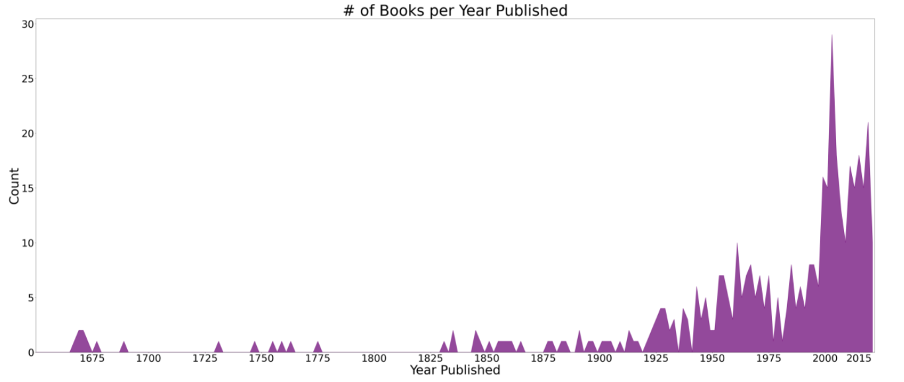
As you can see, most of the books in my library are recent, with the mode (most frequent value) being 2004. 2004 also happens to be the average publication year of the books in my library.
Part 2 - Adding Variables
Though it was fun to have a basic look at the data, the main goal was to be able to build a model capable of predicting how I would grade each book based on how I had graded past books. (Note: I won’t get too descriptive about the code here. I’ve tried to add as much explanation in the code I’ll be displaying. You can also find the entire code on my Github, though I have to warn you it might be a bit messy).
What variables would you focus on if you were trying to predict which book you would like to read? The book’s title? Its author? Its average rating on Goodreads? Its genre? Its Publication Year?
If a computer were trying to do that same exercise it might have trouble using some of these variables for analysis. Indeed, while a book’s title might give a reader a lot of indication about the book, it is much harder (though not impossible thanks to NLP and such) for a computer to understand words and especially what might be appealing in a book’s title or what might be an indication of the quality of a book. This appears particularly difficult given how small our dataset is and how short titles tend to be. On the other hand, numbers and binary variables (eg. is-poetry or is-not-poetry) are much easier for computers to use when building a model.
Instinctively, two variables appear more important than others. First, the genre, as some people absolutely hate poetry or plays or nonfiction... Second, the average rating appears to be a good indicator of the quality of a book and thus of the probability that one will or won’t like the book. While the Goodreads data provided the title, the author, the publication year, the number of pages and the average rating, it did not provide the book’s genre.
I therefore attempted to add that information to my dataset before I started building my model. Yet, this turned out to be more complicated than I thought (as you’ll find out soon enough 😂) If you want to go straight to the model and its results, scroll to Part 3.
2.1 - Google API
I quickly discovered that Google had developed an API where one could provide a book’s ISBN (International Standard Book Number) and have access to plenty of information on that book, including its genre. Therefore, I wrote some code to collect the genres of all the books in the dataset.

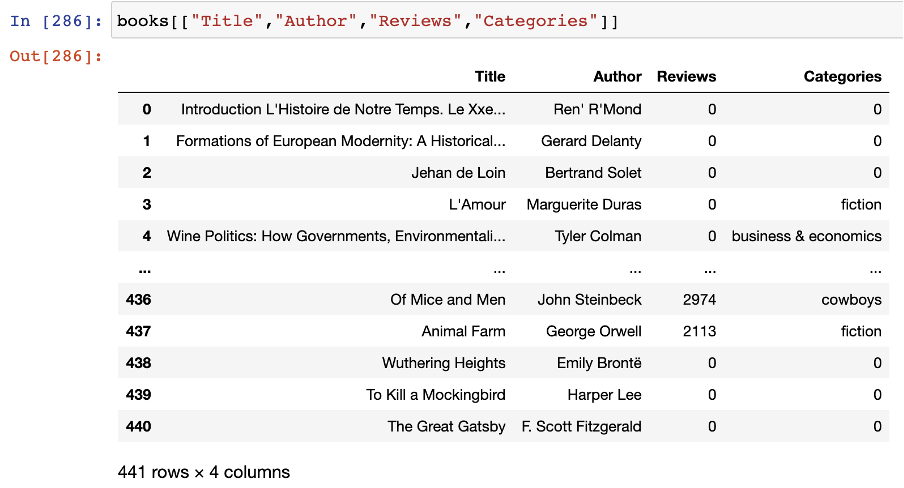
However, after checking out my results I realized that while all the books appeared included in Google API’s dataset, 56.5% didn’t seem to have genres. So even though I was better off than where I had started, my results appeared too limited for analysis as seen below 😐
2.2 - Scraping Goodreads
One of the features I enjoyed with Goodreads was that instead of books being classified under a single genre, they were classified under multiple genres as seen below.
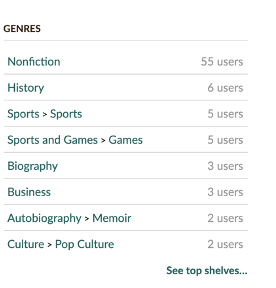
This gave me more insight when checking out a book on the platform. It also came in handy for my prediction model as it would guarantee that all books would be classified in at least one genre, but even better, in multiple genres. I therefore attempted to obtain that information for every book by using "web scraping".
For those unfamiliar with web scraping here’s a short description of how it works: When you check out a website, your browser is making an HTTP request to the website's server, which returns an HTML document. That document is processed by your browser to display the aesthetic and user-friendly website we see and interact with every day. With web scraping, you’re basically creating a program that simulates that HTTP request and then searches into the HTML document to find whatever you had asked him to find.
Thus, whenever you are scraping you need to find a "trick" to access all the URLs you are interested in. If it's not clear now, don't worry! It'll hopefully be easier to understand with the examples below 🙂 To retrieve the genres of a book, I therefore have to know the URL of that given book's website. The key here is to understand that we don't want to manually retrieve all of the books' URLs. Rather, we want to try and find a trick to be able to generate all of them automatically. Scraping is therefore a game of patience, creativity and luck. It’s also why it’s generally considered to be a "last-resort method", which you employ after having failed to obtain data through other means (open data, APIs etc).
As seen in the image below, a book's Goodreads URL can be divided in 3 sections: Goodreads’ basic URL (red), what seems like a Random Number (blue) and the Book's Title (green).

What would happen I deleted the book's title at the end of the URL? As it turns out, it works out fine! As seen below 🙂

So the question now becomes, what does this random number correspond to and how can we find that number for each book in our Library? By going back to the data we originally imported from Goodreads we find that the first column in our dataset actually corresponded to the Book's Goodreads Id. That could be our answer! After trying it out we realize that the "Random Number" is in fact the book's Goodreads Id.
That's great news because we have all of our Goodreads’ Book Ids and we’ll therefore be able to generate all of our Books’ URLs and thus fetch all of their genres! Thanks to Python this can be done super easily in a few lines of code 👇

That's all the code we need! However, when we look at our results, we see that there's a lot of issues! While we obtained what we wanted for our first results, we seem to only obtain empty values for the later ones. 😓

How come? When we look at what we obtain when "scraping" in our later results, we realize that the HMTL code sent by the server contained the following weird results:

This seems to be a voluntary scraping defense created by Goodreads developers to prevent people from scraping Goodreads too much. Thus, while we almost got all of the results we needed, it's sadly not the appropriate solution to our issue.
2.3 - Goodreads API
While I was aware that Goodreads had developed an API, its website indicated that the API remained active but that they had ceased to give out the access tokens required for using the API. Therefore, I originally looked for alternative solutions as the ones mentioned above. Luckily, I stumbled on an API request made by one of the users on a forum. The request included the access token they had used, I was therefore able to use that access token and make my own API requests as seen in the code below!
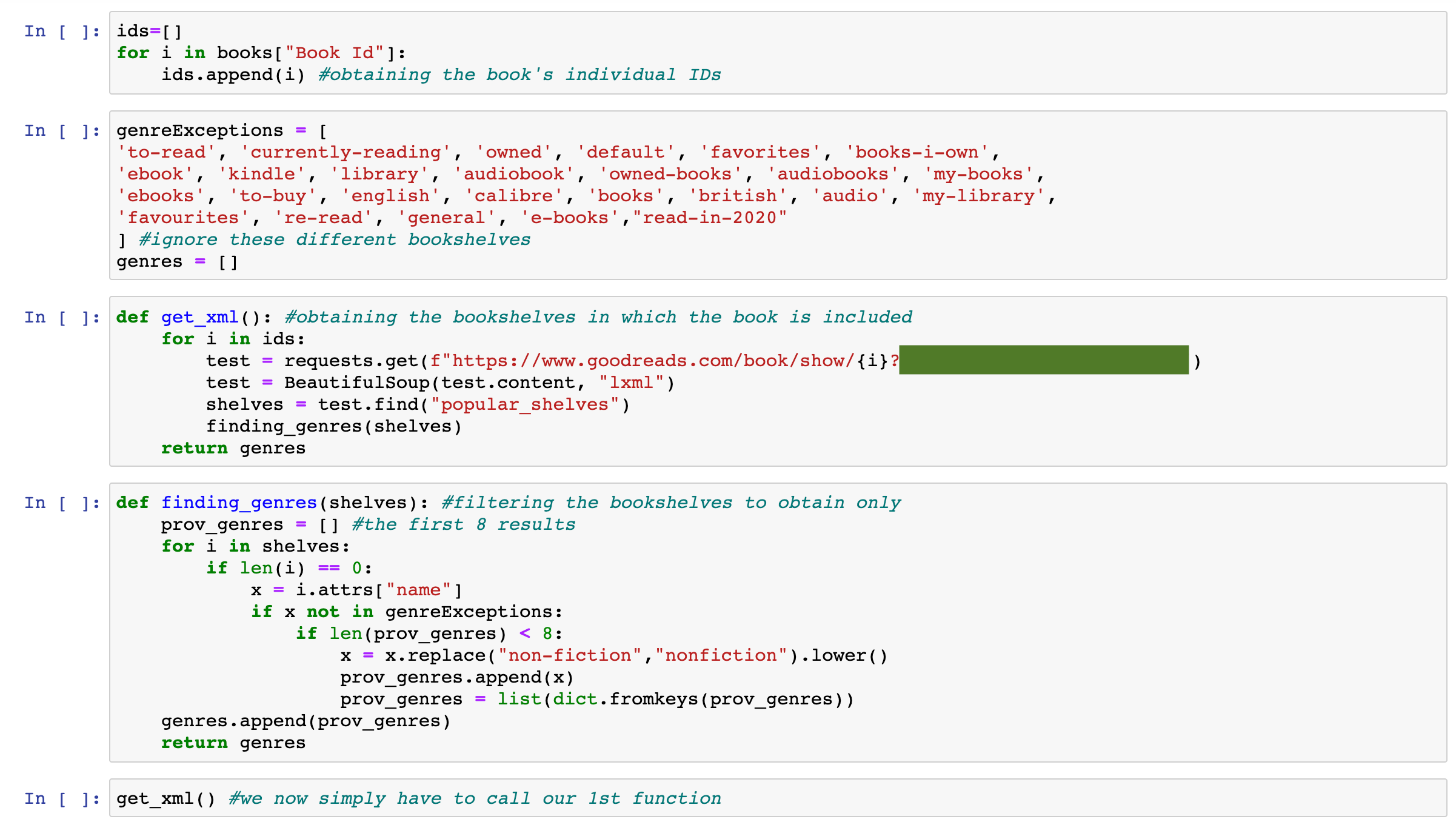
It worked! I now had plenty of genres per book to help me improve my model 💪
Part 3 - Predictions
Now that we have all the information we want, it's time to build a model! I won't go through the code step by step here, remember that it's available here.
When it comes to building a model it’s important to remember what we’re trying to predict. In our case we’re trying to predict the rating I would give a book. Therefore, we’ll be using a type of Machine Learning called Supervised Learning. The basic idea is to allow our model to find patterns for books we have already graded to let him figure out what we like about a book and what we don’t, what’s important and what isn’t, etc so that he can then predict the ratings of books I haven’t read.
I started by using the most basic model, a Linear Regression. Here are the “patterns” he identified!

You can see that my model relied mainly on two things: the average rating (a score between 1 and 5) and the books’ genres. You can see that according to this Linear Regression it seems that I dislike fiction (if a book has fiction in its genres then the predicted rating will decrease by 1.4 points). On the other hand, if the book belongs to the novels or classics genre, then the predicted rating will increase by 1.2-1.3 points.
The only non-binary result in the model was that of the Average Rating whose values range from 1 to 5. The idea is that for every 1 you add to the Average Rating, it adds 0.522... points to the Predicted Rating.
Now that we’ve successfully run our model, we can check out which of the books from my Want-To-Read library the model believes I would prefer. Here are the results! We can clearly observe that while Average Rating appears to have some impact on our Predicted Rating as all of our top books have an Average Rating of 3.5+, the best books aren’t necessarily the ones with the best average ratings.

To make it more accurate, I started using other models. One of them was a Logistic Regression. Check out this article if you want to learn more about the difference between Linear Regressions and Logistic Regressions. The basic idea being that while Linear Regressions construct a linear equation that describes the relationship between dependent and independent variables, Logistic Regressions classify elements of a set into two groups (or more) by calculating the probability of each element of the set.
In our case the model would find patterns to try and make sense of why certain books are graded 1 or 2 or 3… For each book it will then calculate the probability that the book would fit in the category 1 or 2 etc until 5, and will make its prediction based on the category with the highest probability.
I also used K-Nearest Neighbours (KNN) Regression and KNN Classification models. I then calculated the average of the results of the four models to determine my final ranking. The top 15 results can be seen below, with author John McPhee taking both 1st and 2nd place! Check out the full results on my website or on Sheets 🚀

Part 4 - What Comes Next?
Short Term
As you can imagine, there’s a lot that can be improved. First, I’d like to improve my model by adding other variables such as Ratings Count, Number of Pages, and more.
Second, if you had a look at the code, you would have probably seen how badly organized it is. Therefore, I’d like to structure it to make it more suitable for deployment or at the very least to facilitate reproduction. The idea being that every now and then I will re-download my data from Goodreads and see how the results vary thanks to the additional ratings I’ve given books. I also have a lot of friends who use Goodreads. So I also look forward to obtaining their data to give them personalized recommendations!
Long Term
Ultimately, the goal would be to create a mini-website where people can upload their Goodreads data (or rate a certain amount of books) and be given personalized book recommendations. Another possibility could be creating a Chrome extension to make the user experience even better and simpler.
If you have any ideas, suggestions or feedback (they’re always greatly appreciated!) or would like to help me out with the short term and/or long term goals for this project, feel free to leave a comment below or contact me on Twitter @the_simonpastor !
I really enjoyed working on this project and sharing it with you, I hope you enjoyed reading about it 🙂
Good stuff. You should try and test which is most effective of the four models by taking a subset of the books you have already rated as the training set and use the rest to generate ratings with each model and see how this matches up to your actual ratings (for the size of your sample, maybe an 80%-20% split). I’d be interested to see which model matches your rating most accurately. (Also try rotating what books are in the 80 and which are in the 20 to see if that makes a difference.)
Very interesting experience. Thanks for sharing.